予測分析を活用した将来の不正防止計画の策定
Fraud PROGNOSTICATIONS
Predictive analytics can help determine future anti-fraud plans

本記事は”不正分析論:検知と予防の為の戦略と方法(Fraud Analytics:Strategies and Methods forDetection and Prevention)”Delena D. Spann Copyright@2014(John Wiley & Sons)より抜粋、編集したものである。John Wiley & Sons 社 転載許諾済。
Delena D. Spann, CFE, CCA
翻訳協力:田邉 慶周、CFE、CIA
PIC保険の不正検査士であるシルビア(Sylvia)は、難題に直面していた。会社の特別調査部門の責任者として、わずかな予算で部門の運営を行わなければならない中、上司からは、最も深刻な問題を「トリアージ―優先順位付け」できる様、会社における最大の不正リスクを見つけ出すことを求められていた。PICでは、ひき逃げ事故の傷害による損失が増加していた。それに関して、シルビアは全米保険犯罪局(The National Insurance Crime Bureau)から自動車事故詐欺を行っている米国周辺の多くの組織的犯罪集団について聞いていた。さて、シルビアは今後その不正が、あるいは他のスキームが増加していくかどうかを、そして、もし増えていくならば、会社はどの程度の資源をその不正防止プログラムに割り当てるべきかをどうしたら知ることができるだろうか? 解決策は、予測分析とモデル化にあった。
シルビアは、チームスタッツ有限責任会社(Team Stats LLC)を雇った。彼らは、予測分析を使って追加調査が必要な保険請求と、PICが通常の請求処理を進めてよいものを識別するための支援をした。初めに行ったのは、ひき逃げ障害事故の過去の調査記録を分析することだった。この分析から、チームスタッツは15の特性を抽出して予測モデルを構築した。そのモデルは、今後数年間でこの種の不正が増加することを示唆しており、PICはそこにより多くの資源を投入すべきだと判断することになった。
この架空の(しかし、正確な)ケースは、不正リスクモデルによる予測分析の価値を示すものである。
(Three popular predictive modeling methodologies)

長い間、不正検査士は不正や疑わしい行動を検知、予測するために、不正データ分析と予測分析を併用してきた。不正データ分析は過去の行動を特定することに、一方、予測分析あるいはモデル化は、将来の行動を予測することに使われる。
不正検査士は、潜在的な財政への脅威、二重支払、保険不正、クレジットカード不正の検知や、他の多くの活動の中から犯罪が起こりやすい分野のパターンを構築するために予測分析を活用することができる。予測分析は、不正の内容は常に変化しており、それ故不正対策手法もまた変わっていかなければならないことを裏付けている。
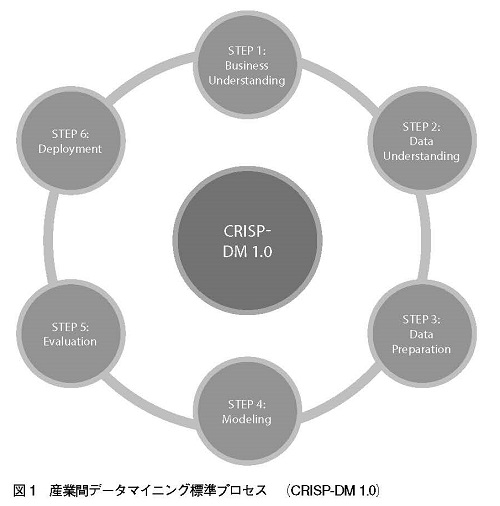
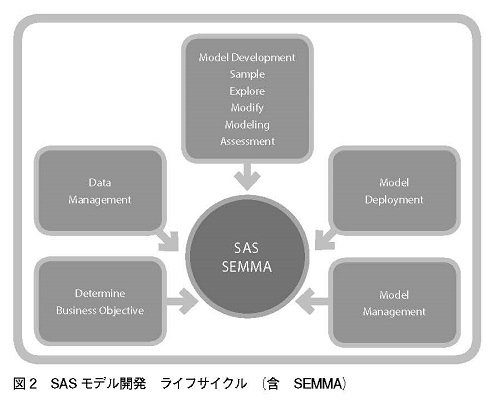
この記事では、3つの予測モデル手法:CRISP−DM1.0、SEMMA併用型SAS、13ステップスコア開発を比較していきたい(それぞれ、図1、図2、表1を参照)。ここでこれらのモデルのすべての詳細について触れることはできないが、以下でいくつかの主要なポイントについて説明していく。
| ステ ップ | データマイニングの 好循環 | CRISP-DM 1.0 | SAS (含SEMMA) | 13ステップ不正 | 分析 |
| 1 | 事業の問題をデータマイニングの問題へ変換 | 事業の理解 | 事業目的の理解 | 事業の問題を解決するための計画の立案 | 指示 |
| 2 | 適切なデータの選択 | データの理解 | データ・マネジメント | データサンプルの選定 | 収集 |
| 3 | データの把握 | データの準備 | モデル開発(含SEMMA) | データ変数の上位集合の選定 | 評価 |
| 4 | モデルセットの作成 | モデル化 | モデル展開 | 記述統計によるデータの集計 | 記述 と 照合 |
| 5 | データの問題を解決 | 評価 | モデルマネジメント | データの整理 | 分析 |
| 6 | 情報を表面に出すためのデータの変形 | 展開 | 派生変数の生成 | 浸透 | |
| 7 | モデル構築 | 変数の数の削減 | |||
| 8 | モデル評価 | 出力変数とモデル化技法の定義 | |||
| 9 | モデル展開 | 統計的モデルの構築 | |||
| 10 | 結果の評価 | モデルの結果の集計 | |||
| 11 | 再開 | モデル結果のテストとモデルプロセスの書面化 | |||
| 12 | プロダクション(実稼働)モデルの実行 | ||||
| 13 | モデルのパフォーマンス監視 |
(Overview of fraud analytics and predictive analytics)
不正分析は、不正が起こったのかどうか、起こったとすればどのように、誰が関与して、いつ発生したのかを特定する為に過去の証跡つまりデータを調査する。かつては、不正分析には基本的な表計算ソフトが使用されてきた。しかし、新たな大変革は否が応にも私達を捉えている。我々は、今や絶えず進化する戦略、データマイニング手法、強力なソフトウェアを駆使している。
逆に、予測分析においては、不正検査士は過去の不正事案から変数の組み合わせを抽出し、それを当てはめることで将来の結果、出来事が不正となる可能性を見極めていく。
不正検査士は、不正分析を予測分析の発展、情報の収集、展開、評価、結果の査定の為に使わなければならないが、不正のデータ分析に予測モデルは必要ない。
もちろん、不完全または不正確なデータは、どちらのプロセスにおいても混乱を招き得るが、予測モデルは、よりデータの質に依存していると言えるだろう。予測モデルは、分析結果に基づく素早い対応から、最も大きな効果の一つをもたらすが、結果がデータの質に悪影響を受けていれば、時間の無駄となる。だが、たとえ時間の効率的活用が分析における重要な要素だったとしても、もし作業の繰り返しや微調整が必要になれば、そのプロセスが大きく変わることはない。効率性と有効性は、ともに不正行為を躊躇させ、検知し、芽を摘み、調査し、起訴していくなかで、必須の要素なのである。
なお、データ分析には標準的な直線的なプロセスがあるが、予測モデルは非線形構造である。
| 不正分析 | 予測分析(モデル化) |
| 既に発生した不正を発見するために過去のデータを使用。 | 将来起こるであろうことを予測するために過去のデータを使用。 |
| 線形プロセス:各段階は順番に実施され、通常は繰り返さない。 | 非線形プロセス:段階を飛ばし、反復することがある。 |
| 仮説は、不正への関与の最初に立てられる。 | 特定のビジネスプロセスに基づきモデルが定義され生成される。 |
| 追加の仮説が立てられた場合、分析段階が当初の見込みより長く続くこともある。 | 新しいデータや異なる変数が発見された場合プロセスは繰り返される。 |
| 仮説は検証され、必要があれば修正される。 | 成功を確認するためにモデルをテストする。必要があれば修正される。 |
| 不正分析は不正を発見し、将来の不正の発見のためのモデルを提供する。 | 不正の兆候を示すプロセスを生成することにより、予測モデルは不正分析の補完のために使用される。 |
| 不正を発見するための分析者の能力にとってデータの質が重要である。 | うまく機能するモデルにはデータの質が重要である。 |
| 入手可能なデータを全て利用する。 | 利用可能なデータのサンプルを使用する。 |
| 統計的な分析を目的として、データ(平均、中央値、最頻値)を組み立てる。 | 不足している変数を補うためにデータを作りだす。 |
| 不正分析は必要があれば実施されるが、定期的に反復されることはなく、最終的な結論が出れば終了する。 | モデルは反復して繰り返され、常に進行中である。 |
| データの中の異常を捜す。 | データの中の異常を捜す。 |
| 結果を予測することはできず、浸透の後に初めて判明する。 | 最終ゴールの結果を具体的に定義しなければならない。 |
(Comparing and contrasting methodologies)
3つの予測モデルは、それぞれ手順の数が異なり、それぞれにある種の目標をもって開始される。SASモデル(SASインスティテュート社(SAS Institute Inc.,)統計・ビジネスインテリジェンスソフトウェア制作会社による開発)は、SEMMA(サンプル(Sample)、調査(Explore)、修正(Modify)、モデル化(Modeling)、評価(Assessment))と併用して初めて完全な手法となるのだが、SASのステップは、詳細で複雑なCRISP−DMに比べてシンプルなモデルである。(CRISP−DM―産業間データマイニング標準プロセス(Cross Industry Standard Process for Data Mining))は、EUのプロジェクトとして5つの企業により開発)
3つのモデル間のもう1つの明らかな違いは、13ステップがそのモデルで一貫してスコアリングを使用するのに対して、CRISP−DMやSASは使用しないことである。(13ステップ手法は、ウェスリー・ウィルヘルム(Wesley Wilhelm)とアラン・ヨースト(Alan Jost)により開発された)
SASの第1ステップはビジネス目標を明らかにすること、13ステップの第1ステップは問題解決の為のモデルデザインを作成すること、CRISP−DMの第1ステップは「ビジネスの状況の理解」を得ることである。13ステップ及びCRISP−DMの最初のステージは、明確にビジネスやプロジェクトの目的を特定する指示を含んでいる。
ビジネスと目標の理解は、予測モデル成功に決定的な要素に見えるが、SASでは、この最初のステップを適切に完了する為に必要な多くの詳細が省略されているようだ。
CRISP−DMと13ステップは、ともにプロジェクトを通じ一貫して、組織を理解し、どの資源(人材、データ、設備、施設など)が利用できるかを見定めることに注力する。これら2つのモデルは、この目的の為に更にステップを踏んで、成功のために完了しなければならないスケジュールとタスクの概略を記した計画、戦略をデザインする。(参照CRISP−DM1.0、段階的データマイニング(CRISP-DM1.0,Step-by-Step Data Mining)P.チャップマン(P. Chapman)、J. クリントン(J. Clinton)、R.カーバー(R. Kerber)、T.カブザ(T.Khabaza)、T.ライナルツ(T. Reinartz)、C.シアラー(C.Shearer)、R.ワース(R.Wirth)著、CRISP−DMコンソーシアム(CRISP-DM Consortium)、2008年、http://tinyurl.com/75ytjh4)
これらのモデルの初期段階に起こる驚くべき違いは、そのプロセスに必要となる計画と準備の量である。SASの第1ステップは極めてシンプルであり、モデル制作者に求められることは、自動化の為に必要な意思決定の種類と、課題に適切なモデリング手法を特定することのみである。そして、CRISP−DMだけが、リスクと緊急時対策を考慮に入れる。難易度の高いタスクを前に、適切なバックアッププランなしに作業を進めるのは考えられないかのようである。加えて、組織が予測モデルの実験を行うことに同意するためには、経営陣はどんな意思決定の前にも、費用対効果の分析を知りたいと思うだろう。CRISPDMは、その情報を提供する唯一のモデルでもある。
続くいくつかのステップは、お互いに他のモデルの複数のステップと関連しており、それぞれがデータの解釈を含んでいる。例えば、SASの第2ステップはデータマネジメントだが、第3ステップであるモデル開発にもデータを扱う局面がある。13ステップの第2ステップから第7ステップは、すべてデータを含む。CRISP−DMの第2、第3ステップは、データが重要な役割を果たす。
明らかに、予測モデルにおいて最も重要なパートの一つは、データを選別し収集する部分である。このタスクは、各手法において、この第二段階で実行される。データに関連するもう一つのとても重要なタスクは、データをクリーニングし、品質が高い状態を確保することである。この重要なステップにおいて、あらゆるデータ入力エラーは修正され、第三者との不一致が取り除かれ、欠測値が削除される。(参照「分析的インテリジェンスの運用:モデル開発における効果的戦略の為の解決策」“Operationalizing Analytic Intelligence: A Solution for Effective Strategies in Model Deployment“SASインスティテュート,2005年)
「分析的インテリジェンスの運用」によれば、SASおよびCRISP−DMは、オリジナルのデータをより重要な基準として位置付ける。SASは、モデル制作者にデータを調査し、パターン、セグメント、変則的な動き、異常値などを見つけ出すよう促す。
CRISP−DMのデータ理解のフェーズにおいても、モデル制作者は「クエリ、可視化、レポートを利用して」データを分析することが課される。これらの2つの手法は、いくつかの異なる情報源からのデータを統合することも考慮する。
一方で、13ステップモデルは、既存の変数や派生した変数を作り出すことに力点を置く。他のモデルでも(SAS SEMMAの修正フェーズやCRISP−DMの第3ステップであるデータ構築フェーズ「データ準備」において)派生変数は使われるが、その役割はそれぞれのモデル化ステップにおけるほんの一部である。13ステップでは、抽出された派生変数は、第3、第4、第6、第7ステップの4つのそれぞれのステップで中心的な役割を果たす。
データに関して言えば、それぞれのモデルは、変数がなぜ、そしてどのようにして作成されたのかが説明される限り、その作成、形式の設定、欠損値の置き換えを認めている。
データが準備されたら、各手法ともモデル化段階に移っていく。SASの第3ステップはモデル開発であり、CRISP−DMの第4ステップはモデル化である。13ステップの第8、第9ステップは、それぞれ、「出力変数とモデル化技法の定義」と「統計モデルの構築」となっている。詳しく調べていくと、これらのモデル化ステップの類似性が見えてくる。この段階のそれぞれのモデルの最初のステップは、適切な技法とツールを選択することである。よく使われる手法には、線形回帰、デシジョンツリー、ニューラルネットワーク、伝統的な統計学などがある。モデル制作者が、この段階で同時に複数の技法やツールを選択することは一般的ではない。特に様々な制約があるときなど、すべての技法があらゆるデータに対応できるというわけではないことが主な理由である。
不正検査士が技法とツールを選択したら、予測モデルの構築の準備が整う。3つの手法で、それぞれモデルを実証、テストするステップを実行していく。CRISP−DMは、モデルの質と有効性を確かめる為のモデルの「テストデザイン」を作り、このプロセスを二重化しているようだが、モデルが構築された後にアセスメントを要求する。一方、他の手法は、テスト環境でモデルの実験をするに留まる。
モデル化段階での次のフェーズは、モデルのアセスメントと評価の両方あるいは一方である。
ここでも、3つの手法はある種のモデルアセスメントを実行する。SASではこれを第3ステップに組み入れ、CRISP−DMでは第4及び第5ステップ(評価)で行う。13ステップでは、第10、第11ステップでこのプロセスの要約と文書化として行う。このアセスメント段階において、モデル制作者は、例えばSASでは新しく発見された課題に直面するかもしれない。CRISP−DMでは、モデルの質を検証し、必要な修正を加えて、定められたビジネスの目的に確実に合わせる作業を行い、あるいは13ステップにおいては、モデルが展開されるべきか否かを決める為に結果を要約することになるだろう。
もし、適切な結果が得られたら、このプロセスの次のステップでは、本番環境へモデルを移すことになる。この段階は、SASの第4ステップ「モデル展開」、CRISP−DMの第6ステップ「展開」、13ステップの第12ステップ「プロダクション(実稼働)モデルの実行」にあたる。一部の人々によれば、展開は予測モデルにおいて最も時間がかかる段階となる。モデル制作者は、モデル展開の為の計画と戦略を立案し、確実に期待通りの運用がなされるようにしなければならない。(参照「分析的インテリジェンスの運用”Operationalizing Analytics Intelligence.”」)
展開は最後のステップのように聞こえるが、手法を完了するにはもう一つの作業が残っている。最後のステップは、SASの第5ステップ「モデルマネジメント」、13ステップにおける第13ステップ「モデルのパフォーマンス監視」、CRISP−DMの第6 ステップ、展開におけるもう一つの部分である。これらの最終ステップは、モデルのメンテナンスの為に必要であり、モデルが正しい判断をしていることを保証するものである。
不正検査士は、何がうまく行き、どこが改善を必要とする領域か結果を考察する最終報告を準備するだろう。SASとCRISP−DMにおいては、時間が経過して、もし新しいデータが利用、入手できた場合や新しい変数が認識された場合には、不正検査士はこれに対応する為にモデルを修正、変更できるようだ。実際、CRISP−DMのほぼすべてのステップでは、レビューを踏まえていつでもそのプロセスをやり直すことができる。SASにおいては、不正検査士は初めに戻ることはせずに、第2ステップからやり直す。同様の循環的なプロセスは13ステップモデルにおいては、第13ステップとそれ以外のどのステップにも見られない。
全体的にみると、SASモデルのSEMMAの部分は、CRISP−DMに比べて簡単で手早く使えるモデルである。SASはより簡潔でコストがかからないが、CRISP−DMはより完全性の高い結果をもたらす。各ステップの作業は3つのモデルの間で異なっている一方で、基本的には非常に類似した活動を含んでおり、最終的には、特定のインシデントの将来の発生を予測するという、同じゴールを目指している。
13ステップはとても冗長で、時間とコストがかかるモデルであるが、月々の支出の検証からある人物の負債の可能性や、クレジットカード口座が延滞するかどうか、するとすればいつか、といったことを推定するような、いくつかのビジネス目的には有効だろう。これは、モデルの初期段階で不正検査士が選ぶ機能の定義や変数による。
異なる管理手順の選択肢、補足的観点や多様な技法を必要とする事項に対応するニーズを考えれば、多くの予測モデルがあることは驚くことではない。あるものは他よりも優れているが、常に完璧なものは一つもない。(私自身は、ハイブリッドな予測分析モデルを作るためにいくつかの予測分析モデルから手順を借用している。表1は様々なモデルに含まれるステップの概略を、表2は、不正分析と予測分析の比較の概観を示している)。
これらモデルのいずれか、あるいは3つの組み合わせは、あなたが主要な不正対策をどこに打つかを決める際の目標設定と予算策定に役立つであろう。
(注:英語版FRAUD Magazine September/October 2014の記事“Fraud Prognostications”で冒頭および2番目のパラグラフに記載されているJanetは誤植であり、正しくはSylviaである。ACFE本部Fraudマガジン編集部との確認の下、本稿ではシルビアに統一した。 ACFE JAPAN 事務局)
|
Delena D. Spann, CFE, CCA, 米国連邦法執行機関に勤務。前ACFE 理事会メンバー。 |
|
補足記事 (Sidebar): Seven basic modeling steps for fraud examiners 不正検査士の為の7つの基本的なモデル化ステップ
|
| Copyright Copyright |